


Nvidia and Meta add in modular server and rack kit, establishing new multivendor AI cluster supply chain
The hyperscale data centre operators club, known as open compute project (OCP) has turned its attention to defining how AI clusters will be standardised and announced an expansion of its Open Systems for AI Strategic Initiative, with approved contributions from Nvidia, including the its MGX-based GB200-NVL72 platform and in-progress contributions from Meta.
The OCP launched this community effort January 2024, and participants are a who’s who of the IT world: Intel, Microsoft, Google, Meta, Nvidia, AMD, ARM, Ampere, Samsung, Seagate, SuperMicro, Dell and Broadcom. The objective for the OCP Community with the Open System for AI initiative is to establish commonalities and develop open standardisations for AI clusters and the data centre facilities that host them, enabling the development of a multivendor supply chain that “rapidly and impactfully” advances market adoption.
In the latest move, Nvidia has contributed MGX based GB200-NVL72 rack and compute and switch tray designs, while Meta is introducing Catalina AI Rack architecture for AI clusters. These contributions by Nvidia and Meta, along with efforts by the OCP Community, including other hyperscale operators, IT vendors and physical data centre infrastructure vendors, will form the basis for developing specifications and blueprints for tackling the shared challenges of deploying AI clusters at scale.
These challenges include new levels of power density, silicon for specialised computation, advanced liquid-cooling technologies, larger bandwidth and low-latency interconnects and higher-performance and capacity memory and storage.
Ditching bespoke
“We strongly welcome the efforts of the entire OCP Community and the Meta and Nvidia contributions at a time when AI is becoming the dominant use case driving the next wave of data centre build-outs,” said Open Compute Project Foundation CEO George Tchaparian. “It expands the OCP Community’s collaboration to deliver large-scale high-performance computing clusters tuned for AI. The OCP, with its Open Systems for AI Strategic Initiative, will impact the entire market with a multivendor open AI cluster supply chain that has been vetted by hyperscale deployments and optimised by the OCP Community.”
“Nvidia’s contributions to OCP helps ensure high compute density racks and compute trays from multiple vendors are interoperable in power, cooling and mechanical interfaces, without requiring a proprietary cooling rack and tray infrastructure — and that empowers the open hardware ecosystem to accelerate innovation,” said Nvidia chief platform architect Robert Ober.
Meta’s in-progress contribution includes the Catalina AI Rack architecture, which is specifically configured to deliver a high-density AI system that supports GB200. “As a founding member of the OCP Foundation, we are proud to have played a key role in launching the Open Systems for AI Strategic Initiative, and we remain committed to ensuring OCP projects bring forward the innovations needed to build a more inclusive and sustainable AI ecosystem,” said Meta VP engineering Yee Jiun Song.
“The timing is right, for collaborative innovations to drive efficiencies using less power, water and lower carbon footprint to impact the next generation of AI clusters that will be deployed by the hyperscale data centre operators and also cascade to enterprise deployments,” said IDC GVP and GM, worldwide infrastructure, Ashish Nadkarni.
Nvidia and Meta at the Summit
The announcement came at the Open Compute Project (OCP) Global Summit, taking place 15-17 October in San Jose, California. At the Summit, Nvidia showcased a wide range of OCP-related solutions, including AI factories, scalable GPU compute clusters, Arm-based CPUs and DPUs, storage and networking.
It also gave a glimpse of the future with its new Nvidia Grace CPU C1 configuration – a single-socket Grace CPU Arm-based server that is ideal for hyperscale cloud, high-performance edge, telco and more – as well as Nvidia GH200 Grace Hopper and Grace Blackwell Superchips.
At the Summit, Meta unveiled its ambitious vision for open AI hardware, showcasing a new AI platform and advanced networking innovations. This included its Catalina rack, designed to handle the growing demands of AI infrastructure with modularity and flexibility. Powered by Nvidia’s Grace Blackwell Superchip, Catalina supports high-power workloads with up to 140kW capacity, featuring liquid cooling and the latest industry standards.
Meta’s largest AI model, Llama 3.1, was also discussed. The 405-billion-parameter dense transformer model, trained on 16,000 Nvidia H100 GPUs, demonstrates Meta’s push to scale AI workloads. Its AI training clusters now run on two 24,000-GPU setups, which is a rapid expansion from earlier deployments. Meta also showed off its ongoing partnership with Microsoft which focuses on further innovations like the Mount Diablo disaggregated power rack, supporting more AI accelerators per unit.
Future of networking hardware
Meta also unveiled its next-generation network fabric for AI training clusters at the Summit. The company introduced two new disaggregated network fabrics and an advanced NIC design, both of which aim to address the increasing scalability, efficiency and flexibility demands of AI workloads. Meta’s believes its contributions to OCP could have a far-reaching impact on the AI ecosystem, enabling companies of all sizes to adopt cutting-edge, open-source infrastructure.
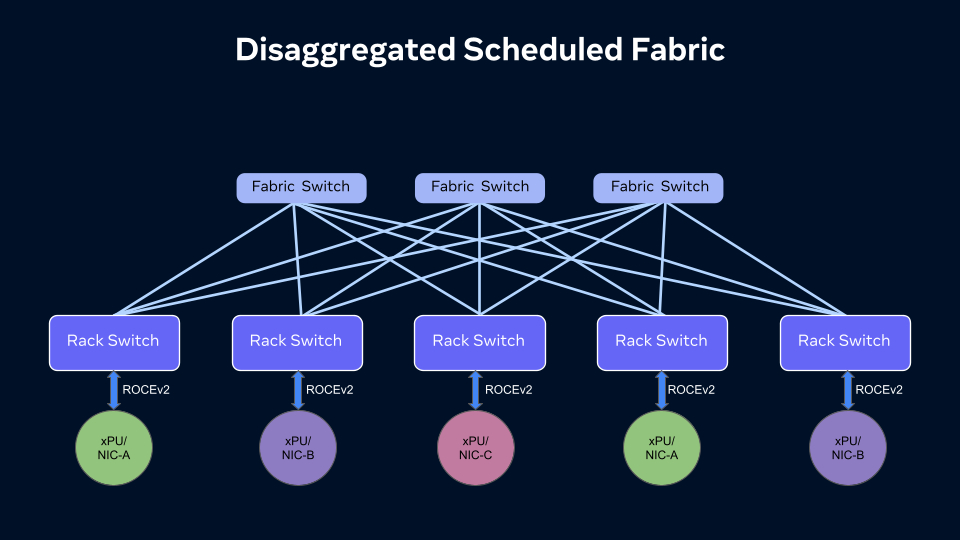
At the heart of this is the Disaggregated Scheduled Fabric (DSF), developed to enhance performance and scalability for AI clusters. By decoupling traditional monolithic network systems into flexible, vendor-agnostic components, Meta said DSF provides proactive congestion management and builds non-blocking, large-scale fabrics tailored to the high bandwidth needs of AI workloads. The fabric is powered by the open OCP-SAI standard and Meta’s FBOSS network operating system, which supports Meta’s MTIA accelerators alongside multiple xPU and NIC vendors.
Meta also announced two state-of-the-art 400G/800G fabric switches – the Minipack3, designed with Broadcom’s Tomahawk 5 ASIC, and Cisco’s 8501, featuring the Silicon One G200 ASIC. These switches offer up to 51.2Tbps capacity and backward compatibility with previous 200G and 400G models, along with optimised power efficiency for AI workloads. Their deployment in Meta’s data centres represents a significant step forward in AI-ready infrastructure, supporting upgrades from 400G to 800G fabrics.
By contributing its disaggregated fabric designs and the new FBNIC – Meta’s multi-host foundational NIC – to OCP, the company continues to drive open innovation in AI infrastructure, enabling developers worldwide to create, adapt, and share new solutions.
Through its collaboration with OCP, Meta reckons it is setting the stage for a more flexible, sustainable, and innovative future for AI-driven data centres.

{kind=link}